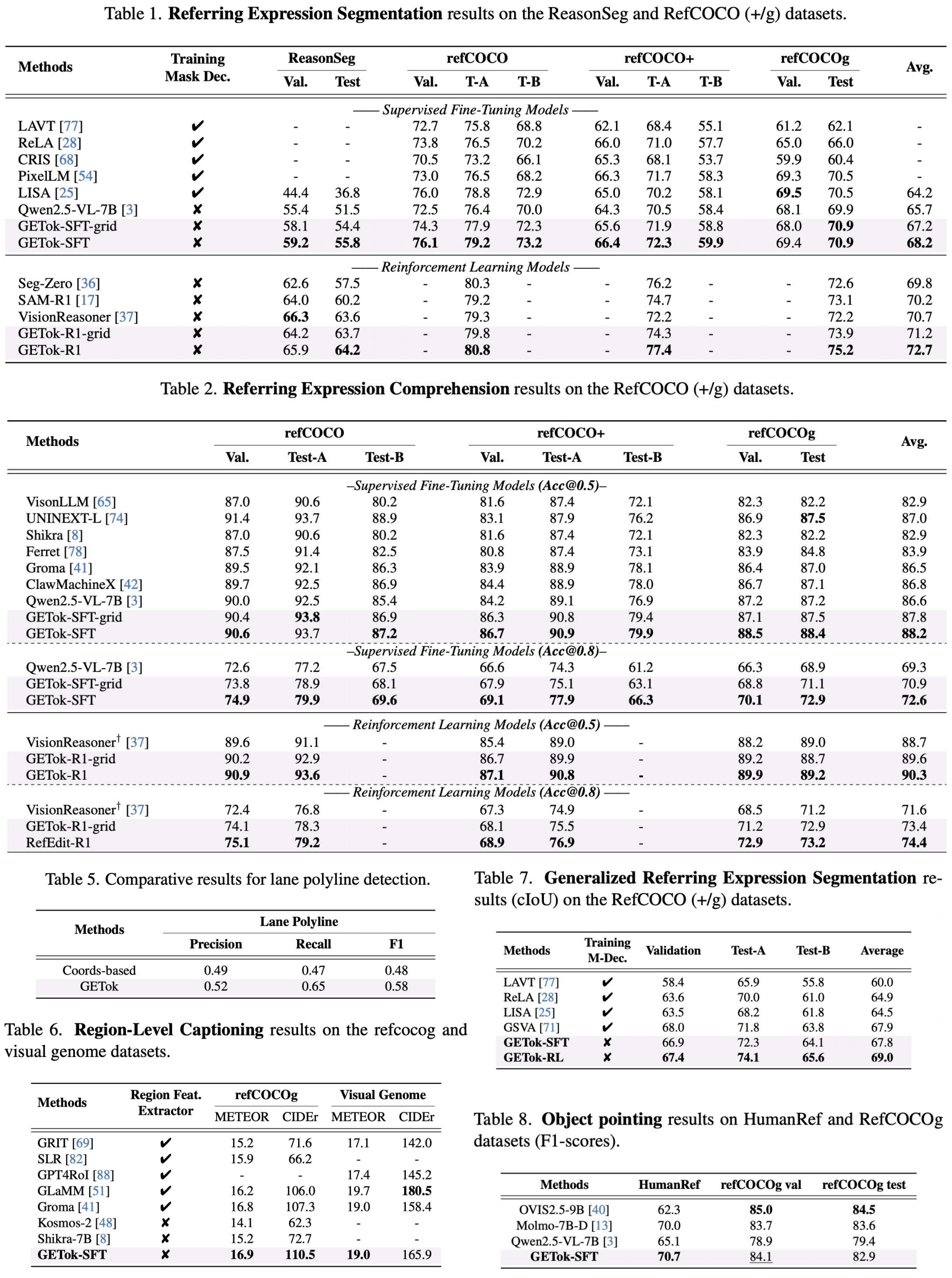
Why GETok?

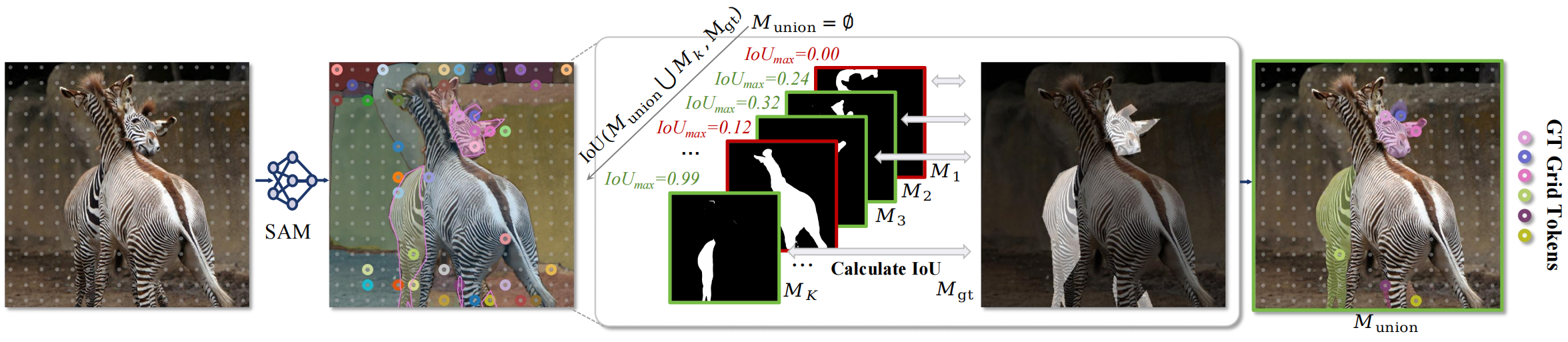
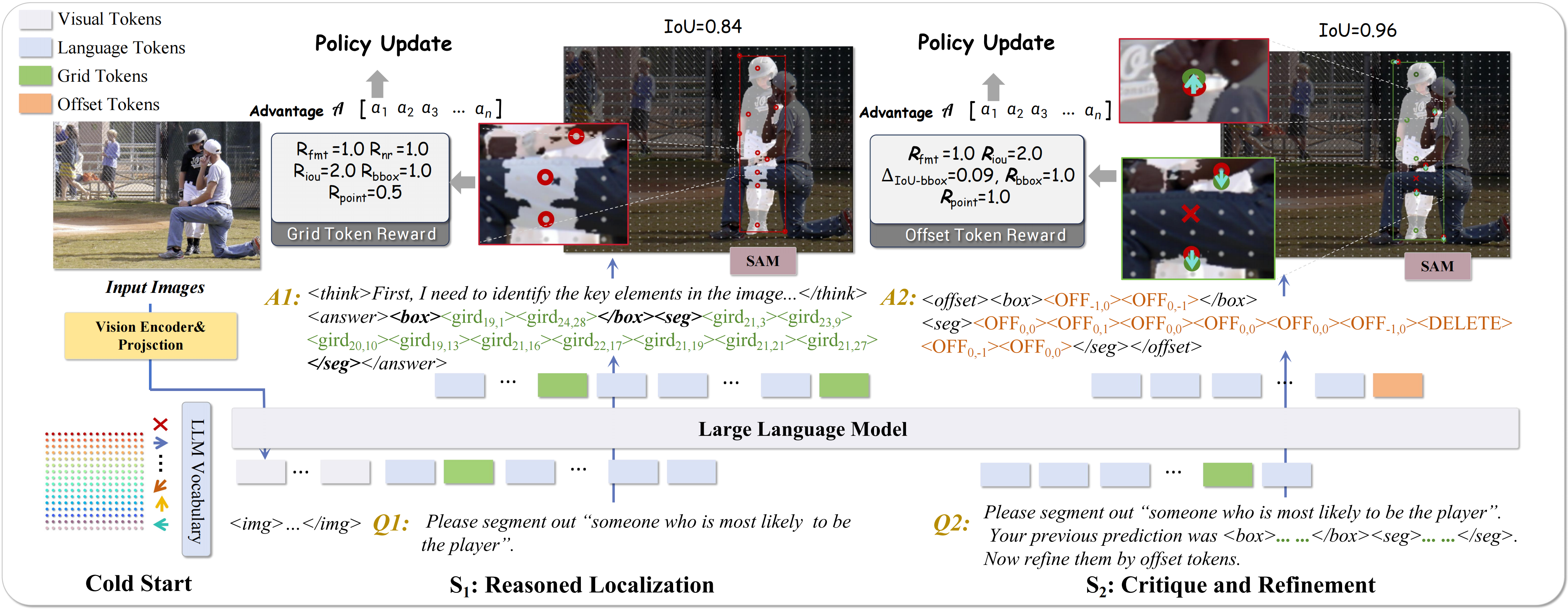
GETok addresses a core bottleneck of MLLMs: image tokenization often discards 2D spatial topology, making precise localization hard. We introduce a learnable spatial vocabulary, with grid tokens that form a 2D anchor lattice and offset tokens that refine locations, so sequential tokens map smoothly to 2D image space.
- Unified Referring Representation: A unified representation from points to masks within a standard autoregressive framework, removing task-specific modules while keeping precision.
- Self-Correction: Iterative refinement with offsets enables the model to adjust spatial predictions and correct early mistakes.
- RL-friendly: Token shifts correspond to smooth spatial changes, yielding a low-entropy action space and stable reward landscapes for efficient policy optimization.